
I wrote this blog post to go along with a lightning talk given at an internal Microsoft performance conference on May 20, 2019.
When attempting to tackle performance improvements in a legacy JS single page application, it can be difficult to know where to start. First and foremost, I want to encourage you to keep chipping away. Profile, profile, profile with Chrome Performance tab in the developer tools. Also add performance events liberally to help you identify bottlenecks in the bootup and runtime performance of your application code.
At Microsoft, I’ve worked for 2 years on improving load times for Yammer. We’re far from where we want to be, but we’ve made a lot of progress. In 2017 when I started working on some of these issues, we were at ~8.5s home (P50) feed load time, the first feed with primary content users see by default when loading Yammer for the first time. Now, we’re consistently hovering around 3.7s (P50), total home feed load time, more than half the original load time!
There are many improvements which have contributed to these improvements, including a long and difficult migration to Azure for all backend services, as well as our asset serving pipeline. But one of the largest contributors has been optimization work we’ve done to reduce Javascript static asset sizes.
The initial effort involved updating our version of Webpack to the latest supporting dynamic import. Converting all our routes to use dynamic import immediately cut ~30% off our 5.55MB total script payload, bringing us down to 3.9MB total. As you can see in the following Gif, this had an immediate effect on reducing feed load times to around 6 seconds.
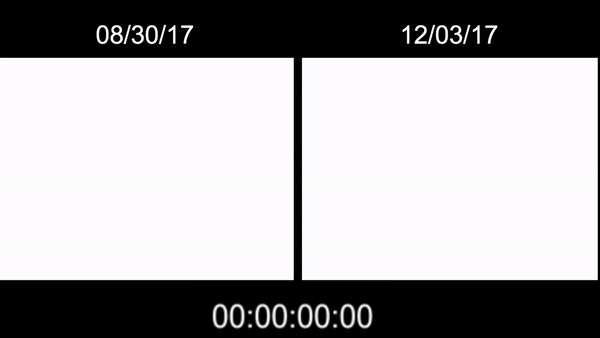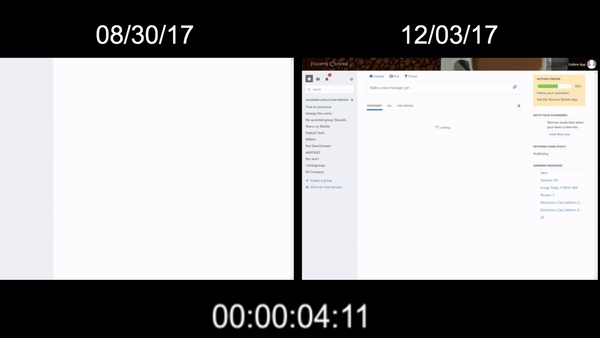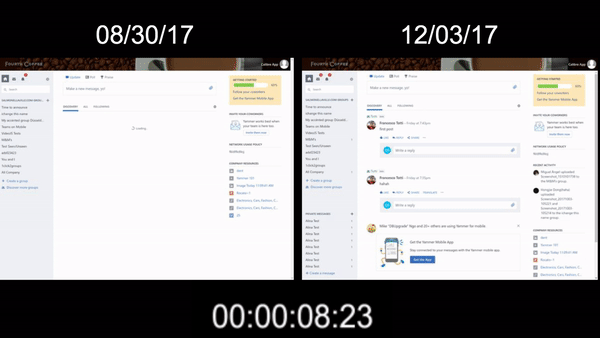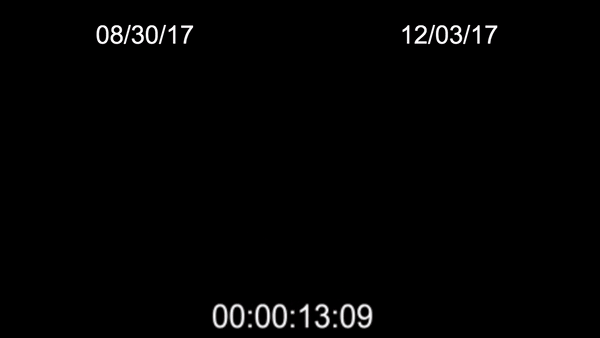
We’ve continued to improve since brining us to about ~723KB total script tranferred when compressed, down from 1.5MB compressed when we started the effort. Yammer has used these techniques to cut our load times in half, your team can too! The rest on this blog post (and the conference talk) focuses on five of the techniques we used to help Yammer load faster:
- Preload and Prefetch to split and prioritize payloads
- Add stable asset fingerprints and infinite cache headers to improve client-side caching
- Use dynamic import techniques and lazy module wrapping utilities
- Ramp up compression with Brotli and Zopfli
- Add fine-grained performance budgets to control output chunk sizes
Prefetch & Preload
<preload>= highest priority
<prefetch>= lowest priority
Take a look at Addy Osmani’s excellent blogpost on script priorities shows how scripts are prioritized by Chrome, outside of a script tag in the head, the preload link tag is highest priority, while prefetch is lowest priority (the browser decides when to fetch, if at all):
| Loading priority (network/Blink) |
Execution priority | Where should this be used? | |
<link rel=preload> +<script async> hack
or
|
Medium/High | High - Interrupts parser |
|
<link rel=prefetch> + <script> in a next-page navigation
|
Idle / Lowest | Depends on when and how the script is consumed. | Scripts very likely to provide important functionality to a next-page navigation.
Examples:
|
If you don’t already have your data bootstrap calls in a separate chunk from the rest of your application code, you can stratigically introduce a new code split point by adding a dynamic import where you call your bootstrap process. We used a promise.all() to start the bootstrap process, fetching initial user and network data, while loading the rest of the application code needed to display the bootstrapped service results.
When you start using dynamic import extensively, it is also helpful to tell the browser about all the chunks, this is what preload is particularly useful for, you can provide a manifest in the initial HTML payload which informs the browser about all chunks you may need to load in the future. The Browser will then treat those links as lowest priority, and only download them (or never download them) based on it’s own heuristics (usually involving network speed and availability).
Add stable asset fingerprints and infinite cache headers
<script src="./app-manifest-be25201d76cbd0b4f9f5.js">
Cache-Control: "public, max-age=31536000, immutable"
Webpack has had multiple regressions and implementation issues in getting chunk hashing stable, we’re currently using one of the last verstions of Webpack v3, but the point releases mattered for us. If your application code has any strings generated at build time, you must be careful to make sure that the output stays the same across builds in order to get stable content hashes.
There’s an excellent article by Andrey Okonetchnikov walking through some of the difficulties of making sure content hashes stay stable. He’s coauthored the latest version of the webpack documentation guilde covering caching, so it’s also a great resourse to checkout: https://webpack.js.org/guides/caching/
Adding the proper cache control immutable header along with a long max-age helps prevent unnecessary network calls to check if a resource has changed. When all assets are generated with stable asset fingerprints, the browser cache will never have to request an identical resource twice. Be careful here, and only limit the addition of this header to assets which contain proper content hashes in their resource names. You can end up preventing users from downloading the latest versions of image assets if you’re not careful.
Use dynamic import techniques & lazy module wrapping
import(/* chunkname */ ./component)Wrap modules lazily
We introduced dynamic import system wide on Yammer at the router level, this yielded a ~30% reduction in initial page load.
You can also use the natural import points between your components in your system to load code right before it’s rendered. Try taking your legacy framework and it’s lifecycle hooks to add a dynamic import wrapper to fetch the source code necessary for component render. It’s also useful to implement a loading indicator for container components for better user experience.
One common tool you can utilize for the React ecosystem is react-loadable:
const LazyBroadcastHubMain = Loadable({
loader: () => import('./container’),
loading: () => <PageMainContentSpinner />,
});
export default LazyBroadcastHubMain;
Another approach you can use in React versions newer than v16.6.0 is to use React.lazy and Suspense APIs to create a similar convenience wrapper to handle async loading of code before mounting the React component.
Ramp up compression with Brotli and Zopfli
Zopfli: very good, but slow, gzip compatible
Brotli: new LZ77 algorithm, modern browser support (IE11)
Zopfli is a “very good, but slow, deflate or zlib compression” (google/zopfli). This means it’s compatible with exisiting browser gzip deflate algorithms, making it compatible without any browser changes needed. But because it takes longer to compress, you shouldn’t attempt to use Zopfli at runtime to compress, you must compress in advance. We chose to use Zopfli to compress all our static assets each time we build the assets. This means increasing build times, but less data transferred across the wire for each asset, and it’s more effective the larger the individual assets are. We saw upwards of ~5% and upward of ~10% size reductions on larger assets, event for legacy browsers.
Brotli is a brand new compression algorithm originally used for fonts but made available for all textual formats. All modern browsers (not IE11) support Brotli, you can see another ~5% to ~20% reduction on your assets when compared to default Gzip compression settings. See Google’s original announcement blog post from 2015 for a great introduction: https://opensource.googleblog.com/2015/09/introducing-brotli-new-compression.html
Bottom line is that increased compression means fewer bytes sent across the wire on initial page load. Legacy applications are particularly great candidates for additional compression if the assets are large and haven’t been code-split yet.
Add fine-grained performance budgets
Webpack supports adding performance budgets which can warn or fail the build if exceeded. These are rought budgets which apply overall to the total size allowed for the largest asset. These are a useful place to start in a legacy application, can help prevent the largest of potential regressions. You might add something like this to your webpack config:
performance: {
maxEntrypointSize: 50000, // 50KB
maxAssetSize: 50000, // 50KB
hints: 'error',
}
A tool we’ve started to use at Yammer, developed by a colleague at Yammer is called toobigrc which doesn’t require webpack at all, tests the declared budget sizes to the size of the files in a dist/ directory. If you’re not use webpack, just use the directory where you put the output files after your asset build. We have restrictions in place that look like this:
{
"restrictions": {
"dist/asset-name.js": "100KB",
"dist/another-asset-name.js": "50KB",
}
}
You can also test the size of the compressed assets by matching on .js.br or .js.gz. The above rules are only testing the size of the uncompressed assets.
I hope you appreciated the overview of helpful tools to help optimize your legacy web application. Feel free to reach out with any further questions, my Twitter and Github handles are both @machineloop.
No Github or Twitter account? Please let me know in the comments or reach out to me at andrew.brassington@microsoft.com