
I’ve always been intruiged by tools that can help make debugging easier and more efficient. I’ve often wondered why I can’t step backward during code execution in the browser, the step forward button seems to beg a corresponding step backward button to match.
This is a challenging problem when executing code because the state of the execution environment changes with every line executed, it’s very difficult to anticipate the differences and restore the previous application state.
At Microsoft, they’ve been experimenting with a new Javascript core for Node called ChakraCore. I’ve had a chance to play with it and it’s pretty interesting, though not perfect yet. (Is software ever perfect? That’s another post for another time)
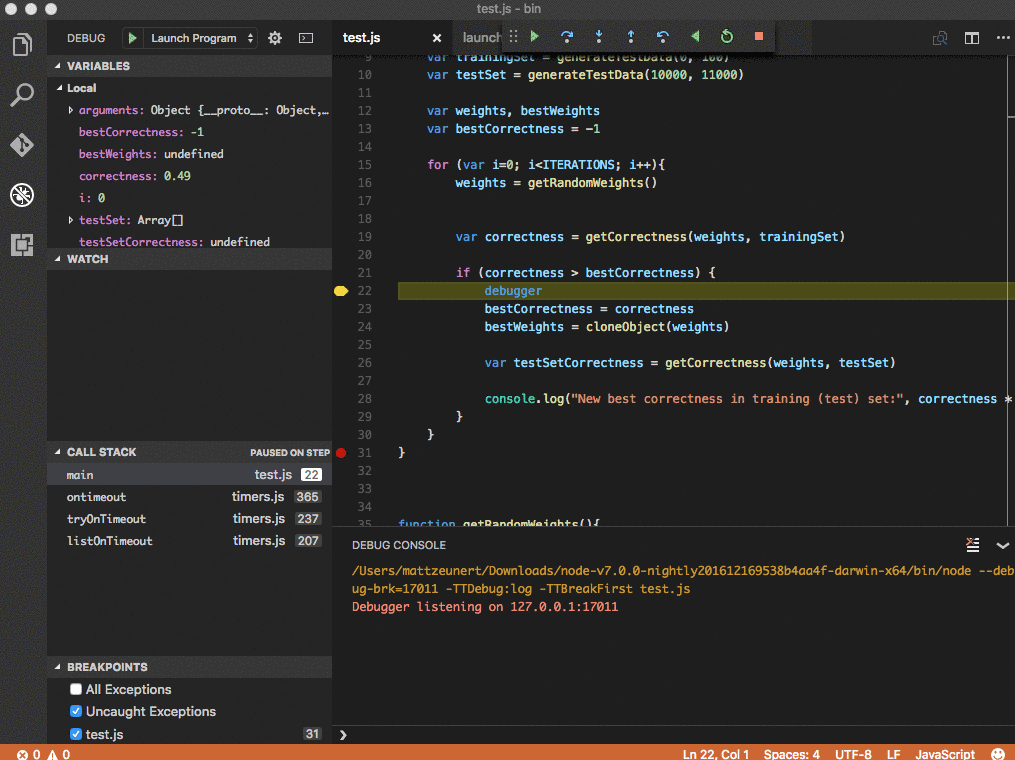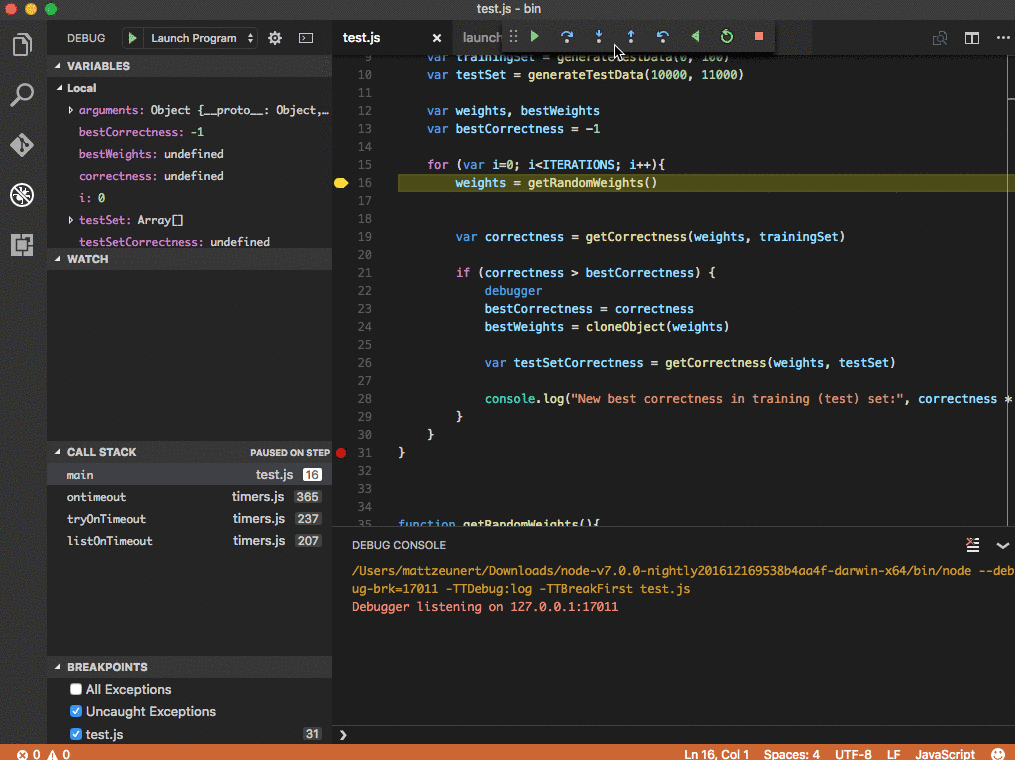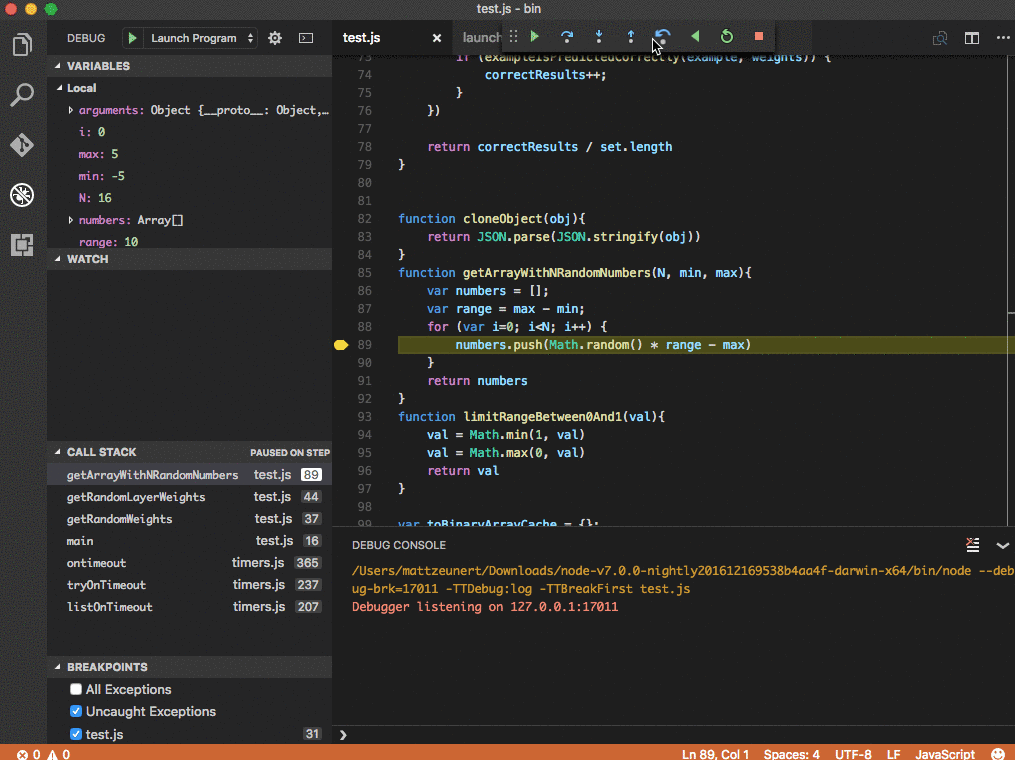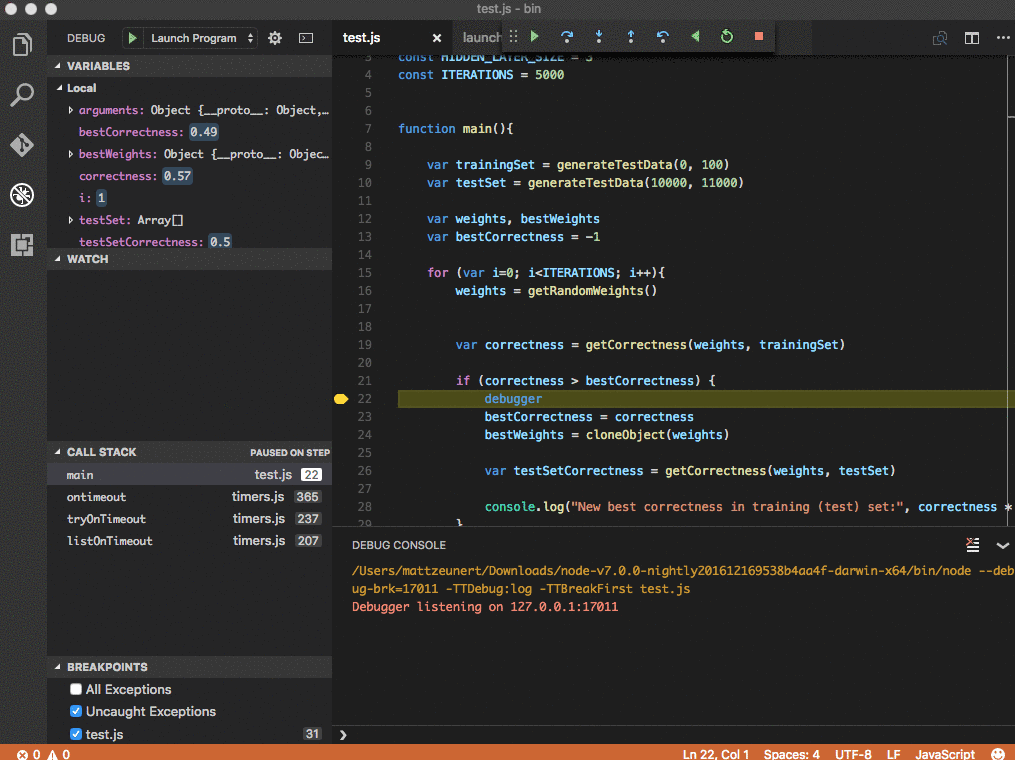
Take a look at Matt Zeunert’s how-to post to get this setup in your environment to try it out.
I immediately asked the question, how is this working? My initial guess is that like the React and Clojure ecosystem, a data structure like a Trie might be involved in storing the differences in state of the world at every line of execution.
Seems that it’s not quite so simple as a single data structre to manage and optimize the recorded state. Basically the approach uses a combination of recording snapshots of the execution state periodically, but also adding a logging mechanism to replay execurtions between snapshots.
The original research was done by Barr and Marron who build Tardis (the name for the time travelling work) into the CLR for C#/.NET environments
A standard approach for implementing a TTD system is to take snapshots of a program’s state at regular intervals and record all non-deterministic environmental interactions, such as console I/O or timer events, that occur between snapshots. Under this scheme, reverse execution first restores the nearest snapshot that precedes a reverse execution target, then re-executes forward from that snapshot, replaying environmental interactions with environmental writes rendered idempotent, to reach the target.
The optimizations are where things get interesting, they piggyback on the CLR Garbage Collector process to store the Heap/Stack execution environment.
JS is also Garbage Collected, so I wondered if they used the same approach for the Node-ChakraCore version?
Check out the work on the Chakra-Node version in this paper, worked on by Barr, Marron, Maurer, Moseley and Seth
I couldn’t find a clear answer to that question, but it seems they used the eventloop to determine when to take snapshots of the environment, basically analyzing the queue and only taking snapshots when items are on the queue scheduled for execution.
Super cool stuff! Can’t wait to use this in my day-to-day workflow, seems like a great tool to have once it’s had more of its bugs shaken out!
What do you think? Let me know in the comments or reach out to me at andrew@brassington.dev